One of our customers asked us to apply an update to their ESXi hosts. Since this is something we do on a regular basis, we did not expect any issues with applying this update. I downloaded the requested updated from vmware and got it ready to install.
I put the host in maintenance mode, started the SSH service, logged in and applied the update. No issues installing the update. To finalize the update I performed a reboot. When performing the reboot of an updated ESXi host, we know that it can take some time, up to 10 minutes.
Not in this case… In the beginning I waited for the host to be available again in vCenter but after about 10 minutes I began to worry. The host was still not available in the vCenter. I logged in to the out of band of the host to verify what was going (I was fearing a PSOD). When I opened the console I saw the familiar black and yellow screen… (No PSOD). But the host was still booting and seemed to hang at starting a service related to storage.
As there was no issue and the host was still busy, I decided to let it continue (thinking it would be done in another 5 minutes or so). In the end, it took the host more than one hour to finish the boot sequence and become available in vCenter again. I had to apply the update to 14 more ESXi hosts, if I had to wait an hour for each host it would take 2 days to finish the job. Not acceptable.
ESXI Slow Boot: Investigation
I now had one host patched, still in maintenance mode and rebooted. To reduce the boot time of the ESXi host, I started with the most obvious culprits. I disabled the usbarbitrator service from auto-starting with the host on the next reboot. I logged back in via SSH and ran the following command:
Chkconfig usbarbitrator off
This action reduced the boot time by a couple of minutes. Not enough to reduce the overall boot time of the ESXi host.
I knew the customer was making use of several windows clusters in a CAB (Cluster across Boxes) approach. This included the usage of several RDM disks. To get a view of the number of virtual machines with RDM disks (physical or virtual) attached to it, I turned to PowerCLI. I ran the following command after connecting to the vCenter instance:
Get-VM | Get-HardDisk -DiskType “RawPhysical”, “RawVirtual” | Select Parent, Name, DiskType,ScsiCanonicalName,DeviceName | FL
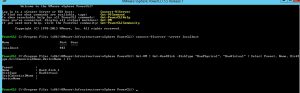
After executing the command, I got back a list of about 22 VM’s with RDM’s attached to them and all were of type ‘Physical’. Next up was to verify if the ‘Is Perennially reserved’ flag was set for all the volumes that had RDM’s on them. The previous command gave me all the naa id’s I needed to verify this.
I logged back in to the Host via SSH and ran the following command (replace the “naa.id” with the naa.id of your storage device):
esxcli storage core device list -d “naa.id”
When you run this command, you will get the info about the datastore. The important part is the flag “Is Perenially Reserved”. When set to ‘False’, it will increase the boot time of your ESXi host. The reason for this is that the active node of the Microsoft cluster has a persistent SCSI reservation on the attached RDM. When you boot the ESXi host to which the RDM device is shared, the ESXi host will try to scan these LUNs. Since this action cannot be completed by the ESXi host, it will keep trying to do a rescan until it times out. It will do this for all RDM devices, which in turn will cause the boot time to increase drastically.
It is possible to mark these RDM Devices as perennially reserved (change the flag to true). When set to true, the ESXi host knows not to scan the RDM device during boot or rescan of datastores. The command used to change this flag from false to true is (replace the “naa.id” with the naa.id of your storage device):
Esxcli storage core device setconfig -d “naa.id” –perennially-reserved=true
Once applied to all RDM devices, I rebooted the host again. This time the host rebooted within 12 minutes.